Программа-собеседник TalkerusО программеTalkerus - программа-собеседник. Как и большинство программ, предназначенных для ведения разговора с человеком, Talkerus не является искусственным интеллектом (или хотя бы слабым его подобием), а лишь имитирует оный. Первая версия программы была мной написана в 1997 году как упражнение в программировании на языке Пролог, который я тогда изучала в университете. Тогда у меня была некая надежда создать маленькую, но Настоящую системку искусственного интеллектика для своих личных целей. Потом я осознала, что на создание приличной базы для такой программы уйдет уйма времени, а вот если создавать "ненастоящий" искусственный интеллект, а лишь имитирующую его программу, тогда никаких проблем не возникнет. Программу я написала за один предновогодний вечер (30 декабря, кажется), а вот базу пополняла очень и очень долго. Объем накопившейся базы - это причина, по которой я впоследствии решила переписать программу под Windows и передать широкой общественности: такое пропадать не должно. Впрочем, как всякая программа подобного рода, Talkerus в значительной степени зависит от людей, пополняющих его базы; соответственно, его характер может меняться. Моя база в большой степени носит отпечаток моего характера; людям с другим характером такая база может не подойти.
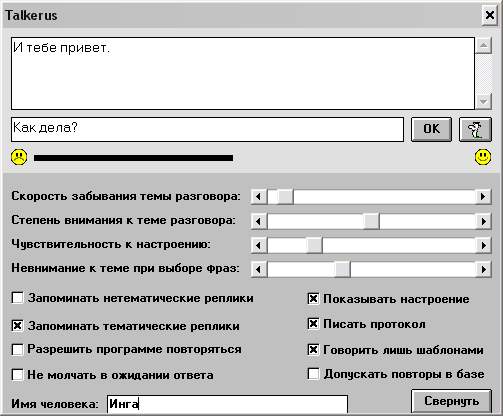
Программа отслеживает некоторые эмоции собеседника, а также свои собственные. Ведется постоянный контроль следующих параметров: общий уровень настроения (собеседника и программы по отдельности) - настроение может меняться плавно, шкала настроения разделена на 1000 частей; уровень отношений (дружеские, нейтральные, враждебные - со множеством промежуточных вариантов); степень агрессии и депрессивности собеседника. Агрессия отслеживается по той простой причине, что многие люди пытаются "наезжать" на программу, ругать ее разными словами, которые программе не нравятся, и т.д.; депрессивность - потому, что изначально я хотела сделать психотерапевтическую программу-собеседник. Возможно, в дальнейшем я добавлю-таки соответствующий блок в программу (дабы Talkerus мог решать, не пора ли погладить человека по головке или, наоборот, дать ему дружеский пинок под мягкое место; пока что он может это делать, но не очень успешно). Значения всех этих показателей в начале разговора - средние (кроме уровня настроения программы, который задается случайным образом); изменяются показатели в зависимости от значения используемых в общении слов. Talkerus также понимает некоторые наиболее часто используемые смайлики ( :), :)), :(, :((, :-(, :-), :0), :-) и др. ). Некоторые из них вызывают соответствующую ответную реплику, некоторые - только изменяют уровень настроения программы и знания программы о ваших эмоциях. Степень чувствительности программы к уровню настроения можно регулировать. Принципы работы Talkerus-аСразу скажу, что какого-то единого, продуманного алгоритма у программы нет; есть смешение нескольких отдельных алгоритмов, давшее в результате нечто, в общем-то, съедобное, хотя и не всегда эффективное. Причина такого смешения - в том, что в последнее время мне хотелось не столько создать Самую Хорошую На Свете Программу (всем известно, какие программы-собеседники в настоящее время считаются лучшими), сколько попробовать, каков будет КПД того или иного нововведения в алгоритме программы. Изначально Talkerus (его версия для DOS) был устроен довольно примитивно. Вводимая человеком фраза анализировалась следующим образом: в ней искались ключевые слова и словосочетания с учетом степени важности, и в зависимости от того, найдены они или нет, выводилась ответная фраза или "пустая реплика" (то есть означающая, что программа не понимает вашей фразы, либо подходящая в качестве ответа на любую фразу человека). Впоследствии некоторые ключевые слова стали запускать отдельные тематические блоки: решение проблемы, возникшей у человека, рассказывание анекдотов, психологическое тестирование, сочинение пословиц и - ограниченно - режим обучения. Основной же блок оставался линейным, на одни и те же фразы всегда выдавались одни и те же ответы, и диалоги могли повторяться. Впоследствии я выделила несколько тем, которые должен "узнавать" Talkerus (по ключевым словам). Фразы, относящиеся к каждой из тем, записаны в отдельный файл. В принципе, можно было собрать все в одном файле, но отдельные файлы человеку не мешают, а программа работает немного быстрее. Честно сознаюсь, что Talkerus, сочтя, что пора сказать фразу на ту или иную тему, берет произвольную фразу из соответствующего файла. Я могла бы сделать так, чтобы в ходе беседы строилось что-то вроде дерева (точнее, произвольного графа) реплик и подбиралась фраза, наиболее подходящая в данной ситуации, но опыт показывает, что овчинка выделки не стоит: одна из фраз в каждой конкретной ситуации не намного лучше подходит, чем какая-либо другая на ту же тему, а создание дерева и поиск по нему отнимают довольно много времени, и программа начинает "тормозить". Тематические реплики Talkerus может использовать (но не обязательно использует) в двух случаях: в случае, если во фразе человека найдено слово или словосочетание, соответствующее данной теме, и в случае, если Talkerus не может понять фразу человека, но помнит, что именно к этой теме относились предыдущие реплики человека. Отслеживаются чуть больше 30 основных тем (в принципе, это количество можно изменить - вручную, и сделать это достаточно легко: просто добавить новый текстовый файл с определенным именем в папку программы; но программное изменение пока не предусмотрено). Каждая фраза (как человека, так и программы) может повышать степень внимания Talkerusа сразу к нескольким темам. Темы, которые были затронуты достаточно давно, постепенно забываются (скорость забывания и степень внимания к теме разговора при слушании и при подборе ответных фраз можно регулировать). В принципе, в программе есть еще один способ подбора ответных реплик, предоставляющий большую свободу действий и позволяющий более точно определить ответную реплику программы. Изначально он использовался для реагирования на ответы типа "да-нет-не знаю". Такой ответ редко бывает полным, поэтому программе необходимо помнить, на какую ее фразу ответил человек. Я создала еще одну базу, содержащую предпоследнюю реплику программы, код ответа человека и реакцию программы. Для интересующихся: код "1" соответствует ответу "Да", "-1" - "нет", "0" - "не знаю", "-2" - человек не ответил на вопрос (сказал фразу, которую программа не смогла идентифицировать как тот или иной ответ). Соответствие фразы человека тому или иному коду частично задается в самой программе, частично - в базе yesno.wrd; в этой базе находятся слова и словосочетания, которые могут входить во фразу, и соответствующие коды ответов. Если во фразе присутствуют сразу несколько словосочетаний из базы, выбирается то из подходящих словосочетаний, которое в базе стоит первым (то же самое, кстати, относится и ко всем остальным базам). В дальнейшем я немного усовершенствовала базу, содержащую "контекстные" реплики программы (reacnext.wrd). Теперь каждая запись этой базы содержит:
Каждый из параметров, кроме ответной реплики программы, может быть заменен на символ подчеркивания: _ , что означает "не важно". Степень соответствия настроения человека и программы соответствующим значениям из базы определяется в зависимости от установленной чувствительности программы к настроению. Кроме этой базы, существует аналогичная пользовательская база нетематических реплик, которая автоматически пополняется при включении соответствующего режима в настройках. По умолчанию этот режим отключен. Дело в том, что запоминать фразу пользователя целиком не имеет смысла: слишком длинные фразы навряд ли повторятся еще раз с точностью до символа. Слишком же короткие фразы могут вызвать поток случайных совпадений. Алгоритм, с помощью которого Talkerus обрабатывает фразу перед запоминанием, достаточно несовершенен и абсолютно правильно работает только с не слишком длинными и не слишком короткими фразами, состоящими из одного предложения (впрочем, такие фразы чаще всего и встречаются в разговоре). Остальные же фразы запоминаются не целиком, и я пока не уверена, что Talkerus правильно определяет, что надо запомнить, поэтому я добавила возможность отключать эту базу. Можно было, конечно, придумать хитрый алгоритм сравнения фраз, но опыт показывает, что такие алгоритмы далеко не всегда работают правильно из-за разных тонкостей великого и могучего русского языка. В базе не обязательно должны присутствовать записи для всех возможных значений параметров. В упрощенном виде обработка программой фразы человека выглядит примерно так:
Естественно, на самом деле алгоритм обработки фразы несколько более сложный: добавляется отслеживание эмоций, нецензурной лексики, есть возможность запретить программе два раза подряд повторять одну и ту же реплику (в принципе, можно было вообще запретить повторы в пределах целого разговора, но я посчитала, что овчинка не стоит выделки, да и в реальном диалоге человек может через десять-пятнадцать реплик по забывчивости задать собеседнику вопрос, который уже задавал, так что особого отличия от "человеческого" разговора тут нет); в некоторые фразы подставляется имя собеседника и другие слова, иногда вместо выбора тематической фразы вызывается одна из дополнительных процедур обработки ответа, параллельно идет процесс обучения (если возможность обучения не отключена) и так далее. У программы есть два режима обучения (разговор на определенные темы и запоминание произвольных реплик). Каждый из режимов обучения можно при желании отключить, а также временно запретить программе использовать выученное.
Примечание. Несмотря на то, что реально первая версия программы была создана в 1997 году, я начала нумерацию версий программы заново, с единицы (версия для DOS была известна слишком узкому кругу лиц; к тому же я немного изменила название программы, хотя алгоритм изменился не очень значительно). |